Adversarial RL for Hard-Negative Code Generation
Abstract
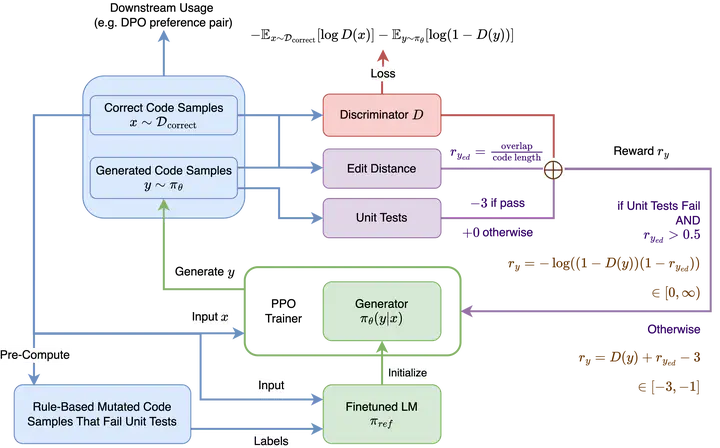
Large language models for code are typically trained on datasets dominated by correct code, limiting their exposure to realistic buggy examples needed for robust training. In this paper, we propose an adversarial reinforcement learning framework for LLMs to generate hard negative examples - code that is deceptively similar to the correct implementation but reliably fails unit tests. Our approach combines PPO with a GAN-style discriminator, rewarding an actor/generator for failing unit tests while fooling the discriminator and maintaining minimal edit distance from reference solutions. Our PPO training dynamics demonstrate effective, iterative updates between the actor/generator and the discriminator. Evaluating our PPO-fine-tuned Qwen2.5-Coder-0.5B on the MBPP dataset, we show that our method can successfully generate hard negative samples through subtle mutations (single character changes, variable swaps) that achieve high similarity to correct code (low edit distance and high discriminator reward) while maintaining 83-89% test failure rates. Compared to rule-based mutations, our PPO-generated negative code snippets are also better suited as preference pairs for downstream DPO fine-tuning, achieving 0.420 pass@1 rate against unit tests for code synthesis tasks.